
You must have heard that C++17 is now feature full or feature complete. C++ 17 is the most recent version of C++ programming language revised by ISO/IEC 14882 standard. Its specification reached the DIS (Draft International Standard) stage in March 2017 and after approval, the final standard was published in December 2017. Hundreds of proposals were put forward for updating the features in C++17.
There must be lots of questions in your mind regarding proposed features added in C++17 as well as whether new compiler updates will include these features. You may also be wondering if C++ will compile in any of the existing C++ Compilers?
I will try to answer such questions in the article below. This article gives you a brief tour of several of the new features of the core C++ language as well as existing features removed from C++.
- Removal of Trigraphs
- Removal of Registers
- Removal of Deprecated Operator ++
- Removal of Deprecated Exception Specifications
- Removal of auto_ptr
- Fixes
- Language Clarification
- Templates
- Attributes
- Simplification
- Library changes – Filesystem
- Library changes – Parallel Algorithms
- Library changes – Utils
- Searchers
Existing C++ Features Removed
First of all, I list down the removed or omitted features from the latest version as compared to previous one.
The draft for the C++17 comprises now 1586 pages because of compatibility requirements. A comparison chart is mentioned below:
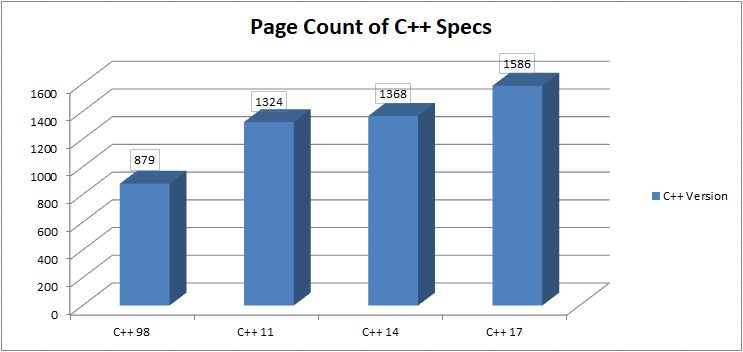
The new features are added and fortunately, there are certain things that could go away.
1. Removal of Trigraphs
Trigraphs are special character sequences. These characters are used when system doesn’t support 7 bit ASCII code – just like in ISO 646-character set. For example ??- produces ~ and ??= generates #. It is important to mention that all basic source character set of C++ fits in 7-bit ASCII.
But the point of discussion is that, these sequences were rarely used. Hence, they are omitted in the current version. The removal of these sequences will make the translation phase simpler.
2. Removal of Registers
The keyword “register” was deprecated in the C++11 standard because it has no meaning. But now in C++17 it has been removed. Although, this keyword is still reserved and may be reused in the future revisions.
3. Removal of Deprecated Operator ++
Increment (++) postfix and prefix expressions are no longer valid for bool operands. This operator is denounced for a very long time. During launch of C++98, it was decided better not to use it. But finally, in C++17, the committee has agreed to remove this operator from the language.
4. Removal of Deprecated Exception Specifications
In C++17, the exception specification is a part of the type system. But still the standard comprises old and deprecated exception specification, which appears to be not practical and in use.
For example:
void fooThrowsInteger(int x) throw(int)
{
printf_s("throw int\n");
if (x == 0)
{
throw 1;
}
}
The above-mentioned code is deprecated since 2011. Only the method “throw()” remains as a synonym for “noexcept()” since C++11.
5. Removal of auto_ptr
The C++11 provides us with smart pointers like shared_ptr, weak_ptr and unique_ptr. Comparatively, auto_ptr was old and buggy thing in the language, so it was deprecated in C++11 however it is finally removed from C++ 17. Almost all features that have been deprecated in C++11 and replaced by superior components, are now no longer included. Although their names are still reserved however the implementations might choose to continue to use these features in future.

C++17 – The Complete Guide: First Edition
Not everything is self-explanatory, combining new features gives you even more power, and there are hidden traps. The book covers the motivation for and context of all new C++17 features with many examples and unique background information for application programmers as well as library developers.
Check C++17 – The Complete Guide on AmazonNew C++ 17 Features
The following features in C++ 17 were added or updated:
- Fixes and deprecation
- Language clarification
- Templates
- Attributes
- Simplification
- Library changes – Filesystem
- Library changes – Parallel Algorithms
- Library changes – Utils
- Searches
1. Fixes
What is a fix in a language standard? According to me, the answer for the question is very simple. Anything missing in the previous versions and included in the current version is a fix.
Auto rules for direct list initialization
Now you can declare a non-type template parameter with a placeholder of type auto. In C++11 we face a strange issue where:
auto x { 1 };
is inferred as initializer_list. This issue is resolved in the new standard, so it will deduce it as int.
Before implementing this, you need to understand the two ways of initialization such as copy and direct.
auto a = foo(); // this is copy initialization
auto a{foo}; // this is direct initialization, it initializes an initializer_list
For direct-initialization, C++17 introduces some new rules:
- For a “braced-init-list” with only one element, auto-deduction will deduce from that particular entry;
- For a “braced-init-list” with multiple elements, auto-deduction will be ill-formed.
For example:
auto a1 = { 21, 12 }; // decltype(a1) is std::initializer_list
auto a3{ 11, 3 }; // error: not a single element
auto a2 = { 11, 3.0 }; // error: cannot deduce element type
auto a4 = { 7 }; // decltype(a4) is std::initializer_list
auto a5{ 8 }; // decltype(a5) is int
Static_assert with no message
This updated feature allows having a condition without passing the message, or you can say that the static_assert declaration now no longer requires a second argument. The version with message is also available. But it is compatible with other asserts such as BOOST_STATIC_ASSERT.
Example
static_assert(std::is_arithmetic_x, "A should be arithmetic"); static_assert(std::is_arithmetic_x); // no such message required in C++17
Varied begin and end types for range based for loops
In C++ 11 range based “for loops” were defined internally as mentioned below:
{
auto && __range=for-range-initializer;
for(auto __begin = begin-exp,__end = end-exp; _begin != __end; ++__begin)
{
for-range-declaration = *__begin;
statement
}
}
In the code above you can see, __begin & __end have the same type. The range based “for loop” is over-constrained. Here, the “end iterator” is never incremented, dereferenced or decremented. It serves no practical purpose being an iterator. This can cause some issues – for example when you use something like a sentinel (denote the end of a range), so it may be of a different type.
C++17 has changed it as follows:
{
auto && __range = for-range-initializer;
auto __end = end-exp;
auto __begin = begin-exp;
for ( ; __begin != __end; ++__begin )
{
for-range-declaration = *__begin;
statement
}
}
Here in the above code, you can see the types of __begin & __end are varied; now only comparison operator is required. This minute change allows the users of Range TS a better experience.
2. Language Clarification
Stricter expression evaluation order
There was no evaluation order were specified in the history of C++ before. The compiler evaluated the operands in random order, and it may choose any other order while evaluating the same expression another time.
Consider the following order of evaluation.
- In f(x, y, z) the order of evaluation a, b, c is still unspecified. But it is sure that one parameter is evaluated fully before the evaluation of next parameter is started.
- Before starting with second point, consider the following example:
With make_unique, in C++17:
foo(make_unique (), nextFunction());
With explicit new, in previous C++ versions:
foo(unique_ptr (new T), nextFunction());
In the above-mentioned code, new T is guaranteed to happen before unique_ptr construction. But if new T happen first, then nextFunction(), and then unique_ptr constructor, it will create a problem.
Because new T generates a leak, when nextFunction throws as the unique pointer is not yet created. The “make_unique”, fixes this issue and it does not allow a leak, even if the order of execution is random.
So, C++17 has fixed the problem with make_unique vs unique_ptr(new T()). By defining the rule that, the function arguments must be fully evaluated before all other arguments.
- We know that the chaining of functions work from left to the right, but order of evaluation of the inner expressions can be different. The expressions are sequenced indeterminately with respect to each other. Now, in C++17, chaining of functions is working as expected, when there are inner expressions, they are evaluated from left to right. For Example x(expX).y(expY).z(expZ)is evaluated from left to right and expX is evaluated first and then b will be called.
- In case of operator overloading, the order of evaluation is determined by the order related with the respective built-in operator:
so std::cout << x() << y() << z() is evaluated as x, y, z.
Consider the following expressions, they will be evaluated in the order x, y and then z:
- y
- x -> y
- x -> *y
- x (y1, y2, y3)
- y @= x
- x[y]
- x >> y
- x << y
And one of the most important parts of the specification is: The initialization of a parameter, including side effects and every associated value computation, is sequenced indeterminately with respect to that of any other parameter.
Dynamic memory allocation
During SIMD ((Single Instruction, Multiple Data) or any other memory layout requirements, you may need to align objects specifically. As, in SSE you require a 16 byte alignment and for AVX 256 you require a 32 byte alignment. So, you will define a vector-4 as follows:
class align(16) vec4
{
float a, b, c, x;
};
auto pVector = new vec4 [1000];
In C++11 and C++14 you have no guarantee of memory alignment. So, you need to use some special routines such as _aligned_malloc /_aligned_free to ensure that the alignment is preserved. It is not a good option as it does not work with C++ smart pointers. As well as, it also makes memory allocations or deletions visible in the code.
But, fortunately C++17 fixes this hole by introducing some additional memory allocation functions that uses align parameter:
void* operator new (size_a, align_val_a); void* operator new [](size_a, align_val_a); void operator delete (void*, align_val_a); void operator delete [](void*, align_val_a); void operator delete (void*, size_a, align_val_a); void operator delete [](void*, size_a, align_val_a);
Now, allocate the vec4 array as follows:
auto pVector = new vec4[1000];
No code variations, but it will magically call the following:
operator new [](sizeof (vec4), align_val_a (alignof(vec4)))
In other words, the word “new” is now aware of alignment of the object.
Exception specifications
In previous versions of C++, exception specifications for a function was not associated to the type of function. In that case, we encountered an error as follows:
void (*t)();
void (**tt)() noexcept=&t; // error: can-not convert to
// pointer to noexcept
struct V { typedef void (*t)(); operator t(); };
void (*k)() noexcept = V(); // error: can-not convert to pointer to noexcept
But now, in C++17 exception specification is a part of type system. One of the important reasons for the addition of this feature is a possibility to allow better optimization. It will happen only when you have an assurance that a function is e.g. noexcept.
In short, you can use the specifier “noexcept” for declaring that a function may throw something or not.
Copy elision
In C++14 and before the standards allow elision in the cases as follows:
- When an object is initialized using a temporary object
- When an exception is caught by the value
- When a variable, which is about to go out of scope is thrown or returned
But it is purely up to the compiler to elide or not. Sometimes elision may happen only in release builds (optimized one), while Debug builds (without optimization) does not elide anything.
C++17 provides us with some clear rules when elision happens. Here, the constructors are entirely omitted.
How it is useful?
It allows to return the objects that are not copyable/movable – As you could now skip move or copy constructors.
It also improves code portability. As it supports “return-by-value” pattern instead of “output params”.
For Example:
struct NotMoveable
{
NotMoveable(int);
// no copy/move constructor:
NotMoveable(const NotMoveable&) = delete;
NotMoveable(NotMoveable&&) = delete;
std::array <int, 1024> arr;
};
NotMoveable make()
{
return NotMoveable(42);
}
// construct_the_object:
auto largeNotMovableObj = make();
The above-mentioned code will not be compiled under C++14, because it lacks copy/move constructors. But, with C++17 the constructors are not needed – as the object largeNotMovableObj will be constructed in place.
Some of the rules for copy elision are as follows:
- glvalue– ‘The evaluation of prvalue calculates the location of a bit-field, object, or function. ‘
- prvalue– The evaluation of prvalue initializes a bit-field, object, or operand of an operator.
Cutting it short: glvalues produces location and prvalues performs initialization.
But unfortunately, in C++17 we will get copy elision for only temporary objects. It does not provide elision for Named RVO. We are expecting that, maybe C++20 will follow it and add some more rules here.
3. Templates
C++ 17 has fortunately bridged the gap between templates deduction rules. So, now the deduction of template may occur not just for functions but also for standard class templates.
You must have used “make” functions for constructing a template object
e.g. std :: make_pair.
But C++ 17 allows you to use a regular constructor forget about them.
Consider the following code:
void t( std::pair ); // call of “t” t( std::make_pair (4.2, 'a'));
The above-mentioned code is valid for C++17 as well as previous versions. As “std::make_pair” is a standard template library function, so here you may accomplish template deduction.
The following is valid only for C++17:
void t( std::pair ); t(std::pair(4.2, 'a'));
It might look identical to you as previous one. But this is not the case, as “std::pair” is a standard template library class. Whereas the template classes cannot allow type deduction during initialization.
Now it is possible to compile the above source code under C++17 language conformant compiler.
Making local variables as pairs or tuples
std::pair p('a', 22);// similarly
std::pair p('a', 22); // here it will deduce the types automatically!It can considerably minimize the complex constructions as follows:
std::lock_guard > lck(mut_ , t1);
The above code can now be transformed as follows:
std::lock_guard lck(mut_ , t1);
Here it is important to consider that partial deduction could not occur. You either need to specify all template parameters or none. Consider the following example:
std::tuple t(‘a’, ‘b’ , ’c’ ); // OK: deduction
std::tuple r(‘a’, ‘b’ , ’c’ );// OK: all arguments are
// given
std::tuple r(‘a’, ‘b’ , ’c’ ); // Error: here partial
// deduction happens
Use auto to declare non-type template parameters
Declaration of non type template parameters is another strategy to use the word “auto” at your desired place. In prior versions, allowed you to use the word “auto” to automatically deduce return types or variables, as well as there are generic lambdas. So, now you may use it for deducing non-type template parameters as well.
Consider the example below:
template void t()
{
}
t<100>(); // t will deduce the type as int
It is suitable, because you do not have to specify an extra parameter for the declaration of the type of non-type parameter. For Example:
template constexpr Type TConst = val;
constexpr auto const MySuperConstant = TConst<char, ‘a’>;
C++17 allows you to do it in a more simple way even:
template constexpr auto TConst = val;
constexpr auto const MySuperConstant = TConst <101>;
Here, you can see that you are not required to write the “Type” explicitly.
One of the most advanced features C++17 offers is Heterogeneous compile time list. Consider the following example:
template struct HeterogenousValueList {};
using MyList1 = HeterogenousValueList<'x', 1000, 'c'>;
Prior to C++17 the declaration of such list was not possible as directly as it is now. In previous versions some wrapper class was needed first for this purpose.
Fold expressions
C++11 provide us with an excellent variadic templates feature. Before C++11, templates (functions and classes) could take a fixed number of arguments. And the number of arguments always specified at the moment when a template was first declared.
While, C++11 lets the template definitions to get an arbitrary number of arguments of different types. For example, prior to C++11 you had to write numerous different versions of a function (e.g. first for first parameter, Second for two parameters, third for three parameters).
But still, variadic templates needed some extra code when you wished to implement ‘recursive’ functions such as sum, all. Here, you had to specify some rules for the recursion:
Example:
auto Sum(){
return 0;
}
Template
auto Sum(X1 s, X... ts){
return s + Sum(ts...);
}
While C++17 provide us even more simple way to write the above mentioned code.
Template auto sum(Argus ...args)
{
return (args + ... + 0);
}
// or
Template auto sum(Argus ...args)
{
return (args + ... );
}
Now let’s have a quick look on fold expressions over parameter packs.
| Expression | Expansion |
| (… op pack) | ((pack1 op pack2) op …) op packN |
| (init op … op pack) | (((init op pack1) op pack2) op …) op packN |
| (pack op …) | pack1 op (… op (packN -1 op packN)) |
| (pack op … init) | pack1 op (… op (packN -1 op (packN op init))) |
And for empty parameters packs(P0036R0) we get the following default values:
| Operator | Default values |
| && | true |
| , | void() |
| || | false |
Here I am mentioning the implementation of “printf” using fold expression:
Template
void FoldPrint(Argus&&... args) {
(cout<< ... << forward(args));
}
And following is the implementation of fold over a comma operator:
Template
void push_back_vec(std::vector& v, Argus&&... args)
{
(v.push_back(args), ...);
}
Cutting it short, fold expression makes a code cleaner, shorter and easy to read.
constexpr if
On the basis of a constant expression condition, the constexpr if feature leases you to drop the branches of an “if statement” at the compile-time.
Consider the following code:
if constexpr(condition)
state1; // Drop if condition is not true
else
state2; // Drop if condition is true
For example:
template
auto get_value(X x) {
if constexpr (std::is_pointer_v)
return *x;
else
return x;
}
It avoids a great deal of the requirement for SFINAE and tag dispatching and even for #ifdefs.
4. Attributes
An attribute is a kind of some additional information that a compiler used to generate code. It could be utilized for optimization of code (like OpenMP, DLL stuffetc.).
As compared to other languages such as C#, in C++ meta information is already fixed by the compiler. User-defined attributes cannot be added here. While, in C# you can only ‘derive’ from “System.Attribute”.
Attributes in C++11 and C++14
C++11 performed one step to reduce the requirement to use vendor specific syntax. The First thing:
In C++11 allows you to specify a nicer form of annotations over your code.
The basic syntax is:
[[namespace::attr]] or [[attr]]
You can use [[attr]] for almost anything: functions, enums, types, etc.
For example:
[[xyz]] void foo()
{
}
We have following attributes in C++11:
- [[noreturn]]
For example: [[noreturn]] void terminate () noexcept;
- [[carries_dependency]]
It mostly to helps in optimizing multi-threaded code
C++14 provides some additional attributes:
- [[deprecated]]
- [[deprecated(“reason”)]]
It is important to note that there is no need to use attributes for alignment as we already have a separate keyword for that i.e. alignas. Prior to C++11 in GCC the following keyword were used __attribute__ ((aligned (N))).
Now at this point you have a clear picture of attributes offered by C++11 and C++14. So now let’s get to C++17.
Attributes in C++17
With C++17 we get 3 additional standard attributes
- [[maybe_unused]]
- [[fallthrough]]
- [[nodiscard]]
As well as three supporting features.
[[fallthrough]] attribute
It specifies that a fall-through in a “switch statement” is intentional and a warning must not be issued for it.
switch (x) {
case 'x':
func1(); // Warning! Fall-through might be a programmer error
case 'y':
func2();
[[fallthrough]]; // Warning suppressed, fall-through is o.k
case 'z':
func3();
}
[[nodiscard]] attribute
[[nodiscard]] stresses on the fact that the return value of a function should not be discarded, due to the pain of a compiler warning.
[[nodiscard]] int foo();
void bar() {
foo(); // Warning! return value of a
// nodiscard function is discarded
}
This specific attribute may also be applied to types, to mark all functions which return that particular type as [[nodiscard]]:
[[nodiscard]] struct DoNotThrowMeAway{};
DoNotThrowMeAway i_promise();
void oop() {
i_promise(); // Warning emitted, so return value of a
// no discard function has been discarded
}
[[maybe_unused]] attribute
This function suppresses compiler warnings regarding unused entities while they are declared with [[maybe_unused]] attribute.
static void impl() { ... } // Compilers can generate warning about it
[[maybe_unused]] static void impl1() { ...} // Here the Warning is suppressed
void foo() {
int a = 40; // Compilers can generate warning about it
[[maybe_unused]] int b = 40; // Here the warning is suppressed
}
Attributes for namespaces and enumerators
It permits attributes on namespaces and enumerators.
enum X {
foobaar = 0,
foobal [[deprecated]] = foobaar
};
X x = foobal; // Omits warning
namespace [[deprecated]] old_stuf{
void legacy();
}
old_stuf::legacy(); // Omits warning
Ignore unknown attributes
Prior to C++17 whenever you tried to use some compiler specific attributes, you might get an error while compiling in some other compiler that is incompatible to it. Now, in C++17 the compiler simply omits the attribute specification and would not report anything. This was not mentioned in the standard, so required a clarification.
// compilers that does not support // MyCompilerSpecificNamespace would ignore this attribute [[MyCompilerSpecificNamespace ::do_special_thing]] void foo();
As in in GCC 7.1 there’s a warning:
warning: 'MyCompilerSpecificNamespace ::do_special_thing' scoped attribute directive ignored [-Wattributes] void foo();
Using attribute namespaces without repetition
In P0028R3 and PDF:P0028R2, this feature was known as “Using non-standard attributes”
It simplifies the way to use multiple attributes, such as:
void func() {
[[rpr::kernel , rpr::target (cpu , gpu)]] // repetition
do-task ();
}
Proposed modification:
void func() {
[[ using rpr: kernel , target (cpu , gpu) ]]
do-task ();
}
This simplification will aid in building tools, which automatically translates annotated codes into several different programming models.
5. Simplification
You might have observed that most of the updated features of language are there for writing cleaner/simpler code. C++17 covers the following features for the simplification of code.
Structured Binding Declarations
I’ve already mention “tuples” in the article above. If you have not started working with the tuples yet, I would recommend you start looking into it right now. Because they not only return many values from a particular function, as well as have specific language support. So that the code is even looks more clear and easy to read.
Consider the following code:
std::set mySet1;
T val{40, "Testset", 3.24};
std::set:: iterator iterat;
bool insert1;
// it will unpack the return value of insert1 into iterat and insert1
std::tie(iterat, insert1) = mySet1.insert(val);
if (insert)
std::cout << "Value was successfully inserted \n";
In the above-mentioned code, you can notice that you first need to declare “iterat” and “insert”. And after that you may use “std :tie” to let the magic happen. But still, it is a bit of code.
You can do it in a more simple way with C++17:
std::set mySet1;
S val {40, "Testset", 3.24};
auto [iterat, insert] = mySet1.insert(val);
So, you can see that a three-line code has reduced to one. And it is easier to read as well as safer.
Furthermore, it now allows you to use const and write const auto[iterat, insert].
Here it is important that Structured Bindings are not only work for tuples alone. We also have other three cases as well:
Case # 01:
If the initializer is an array:
// work with arrays:
int arr[3] = { 2, 3, 4 };
auto [x, y, z] =arr;
Case # 02:
If the initializer supports std::tuple_size<> as well as offers “get()” method:
auto [x, y] = myPair; // it binds myPair . first / second
Or you may provide support for classes, assuming you add get interface implementation.
Case # 03:
If the type of initializer comprises only non-static, public members:
struct X { int a1 : 2; volatile double b1; };
S func();
const auto [ a, b ] = func();
Now getting a reference to a tuple member is as well quite easy such as:
auto& [refW, refX, refY, refZ] = myTup;
And one of the amazing usage is support to for loops:
std::map mMap;
for (const auto & [x,y] : mMap)
{
// k - key
// v - value
}
std::map mMap; for (const auto & [x,y] : mMap) { // k - key // v - value}
You might have heard another name for this feature i.e. “decomposition declaration”. Structure binding and decomposition declaration both names were in use, but now the standard sticks with “Structured Bindings.”
Init-statement for if/switch
The new versions of switch and if statements for C++ is as follows:
switch (init; condition). if (init; condition)
In prior versions of C++17 you had to write:
{
auto value = GetValue();
if (cond(value))
// if cond is true
else
// if cond is false...
}
Here, the “value” has a separate scope, without that it will ‘leak’ to enclosing scope.
Here, you can write it as:
if (auto value = GetValue();
cond(value))
// if cond is true
else
// if the cond is false
In the above-mentioned code value is only observable inside the “if and else” statements, so it does not ‘leak.’
cond may be any condition, not only if value is true/false.
Now let’s see how is it useful?
Let’s suppose you want to look for few things in a string:
const std::string myStrin = "This world is beautiful ";
const auto search = myString.find(" world");
if (search != std::string::npos)
std::cout << search << " world\n"
const auto search2 = myString.find(" beautiful");
if (search2 != std::string::npos)
std::cout << search2 << " beautiful\n"
You are required to use different names for search or to enclose it with a different scope:
{
const auto search = myString.find" world");
if (search != std::string::npos)
std::cout << search << " world\n"
}
{
const auto search = myString.find("beautiful");
if (search != std::string::npos)
std::cout << search << " beautiful\n"
}
The updated if-statement allows you to create the additional scope in one line:
if (const auto search = myString.find("world"); search != std::string::npos)
std::cout << search << " world\n";
if (const auto search = myString.find("beautiful"); search != std::string::npos)
std::cout << search << " beautiful\n";
As stated earlier, the variable that has been defined in the if-statement is as well observable in “else” block. Hence, you can write it as:
if (const auto search = myString.find("beautiful"); search != std::string::npos)
std::cout << search << " beautiful\n";
else
std::cout << search << " not found!!\n";
In addition, you can use it with structured bindings as well;
// if initializer + structured bindings
if (auto [itr, succeed] = mMap.insert(val); succeed) {
use(itr); // ok
} // itr and succeed are destroyed here
Inline variables
With Non Static Data Members initialization, we can now initialize as well as declare members variables at single place. But still, you are required to define them in a cpp file with static variables or const static.
constexpr and C++11 allows to define and declare static variables at one place, but it is restricted to constexpr only.
In prior versions only functions could be stated as inline. But with C++17 you can do the same with variables as well, inside a header file.
struct MyClassExample
{
static const int sValue;
};
inline int const MyClass::sValue = 111;
Or even:
struct MyClassExample
{
inline static const int sVal = 111;
};
Furthermore, constexpr variables are “inline” indirectly, so there is no need to use constexpr inline mVar = 10;.
You must be thinking that how it can simplify the code?
As, many of the header only libraries can restrict the no. of hacks (e.g. using inline templates functions) and only use inline variables.
Its benefit over constexpr is that, the initialization expression does not have to be constexpr.
constexpr if
I have already mentioned this feature above under the heading of templates. There it was just a brief description, now you can will see some more examples that will shed an extra light on this feature.
I hope you can recall “constexpr if” is used to substitute many tricks, which were done already:
- SFINAE technique to eliminate nonmatching method over-rides from the overload set
- Tag dispatch
- You may wish to see at places in std::enable_if in C++14- which was easily substituted by “constexpr if”.
Hence, in most of the cases, now you can now write a “constexpr if” statement to produce more clean code with same functionality. It is essential for template code or metaprogramming because they are bit complex by nature.
Consider the following example of Fibonacci series:
template
constexpr int fibonacciseries() {return fibonacciseries() + fibonacciseries(); }
template<>
constexpr int fibonacciseries<1>()
{
return 1;
}
template<> constexpr int fibonacciseries<0>()
{
return 0;
}
Whereas, the above-mentioned can be written in a ‘normal’ (this is a no compile-time version):
template
constexpr int fibonacciseries()
{
if constexpr (T>=2)
return fibonacciseries() + fibonacciseries();
else
return T;
}
Jason Turner makes an example in “C++ Weekly episode 18”, which demonstrates that “constexpr if” would not do any such short circuit logic, for the compilation of entire expression:
if constexpr (std::is_integral::value &&
std::numeric_limits::min() < 10)
{
}
In the above-mentioned code, for “N”, which is std::string you will have a compile-time error. The reason is that, there are no numeric limits defined for strings.
Consider the following example, here “constexpr if” may define “get” method – which would work for structured bindings.
struct T
{
int a;
std::string x;
float f;
};
template
auto& get(T& t)
{
if constexpr (S == 0)
return t.a;
else if constexpr (S == 1)
return t.x;
else if constexpr (S == 2)
return t.f;
}
While in prior versions you would have required to write as follows:
template <> auto& get<0> (T &t) { return t.a; }
template <> auto& get<1> (T &t) { return t.x; }
template <> auto& get<2> (T &t) { return t.f; }
Now here the question arises, which code is most simpler here. As in above case, I have mentioned just a simple “struct”, with some real life examples. “constexpr if” have made the code cleaner.
As we all know that, C++ is an old programming language, but still its SL (Standard Library) skips a few basic things. The features that are present in .NET or Java for years but were/are not present in STL. Fortunately, C++17 made a great improvement: and now you have the standard filesystem!
Nested Namespaces
Namespaces in C++ provide a method for preventing name conflicts in large projects. C++17 simplifies nested namespace definition. So, nested name spaces can be declared as following:
namespace A::B::C
{
}
Which is equivalent to:
namespace A {
namespace B {
namespace C {
}
}
}
6. Library changes – Filesystem
As I mentioned earlier, SL (Standard Library) lacks some essential features, like you used to use Boost with its multiple sub-libraries to accomplish your work. The C++ Community and Committee agreed that “Boost libraries” are so of great importance that many systems merged into the Standard. Some examples are regular expressions, smart pointers (C++11 has amended it with move semantics) etc.
Similar case happened with the filesystem. So, let’s begin our topic to get an idea, what is inside.
Compiler/Library support
Depending on your compiler’s version, you may need to use the namespace std::experimental::filesystem. Consider the following:
- GCC: when you want filesystem, you need to specify -lstdc++fs. Implemented in experimental/filesystem.
- Visual Studio: In Visual Studio 2017 you still need to use the namespace std::experimental, it uses TS implementation.
- Clang must be ready with Clang 5.0
Examples
For all examples mentioned below, I have used VS 2017.2.
Working with the Path object
“path” object is the core part of the library. By just passing it a path string, you will have access to a number of useful functions.
Let’s examine a path in the example given below:
namespace f = std::experimental::filesystem;
f::path pathToShow(/* ... */);
cout << "exist() = " << f::exists(pathToShow) << "\n"
<< "root name() = " << pathToShow.root_name() << "\n"
<< "root path() = " << pathToShow.root_path() << "\n"
<< "relative path() = " << pathToShow.relative_path() << "\n"
<< "parent path() = " << pathToShow.parent_path() << "\n"
<< "file_name() = " << pathToShow.filename() << "\n"
<< "extension() = " << pathToShow.extension() << "\n";
<< "stem() = " << pathToShow.stem() << "\n"
Output for the path like “D:\Documents\Text.doc” would be:
exist() = 1 root name() = D: root path() = D:\ relative path() = Documents\ Text.doc parent path() = D:\Windows file_name() = Text.doc extension() = .doc stem() = Text
The above-mentioned code is so much simple to use, still there is more awesome stuff:
Let’s suppose you wish to iterate all terms of the given spath, so for that write the code below:
int a = 0;
for (const auto& parts : pathToShow)
cout << "path element: " << a++ << " = " << parts << "\n";
The output of the above code would be:
path element: 0 = D: path element: 1 = \ path element: 2 = Windows path element: 3 = system.ini
I have a lot of things here for you to consider:
- The path object is indirectly convertible to std::string or std::wstring. Thus, you only have to pass a path object into any file stream function.
- You may initialize it with a string. It also provides a support for string_view. So, no need to convert any such object to stringbefore passing it to the path.
- pathhave begin() as well as end() functions that allows iterationover every part.
Now let’s get to the composition of a path.
For that, we have two options such as using append or operator +=, or operator /=.
- concat – it only adds a string without any separator.
- append – it adds a path along with a directory separator.
Consider the following example:
fs::path path1("D:\\Documents");
path1 /= "user";//append
path1 /= "data";//append
cout<< path1 << "\n";
fs::path path2("D:\\Documents\\");
path2 += "user"; // concatenation
path2 += "data"; // concatenation
cout<< path2 << "\n";
Output:
D:\Documents\user\data D:\Documents\userdata
Now let’s see how can we find the size of a file by using “file_size”:
uintmax_t ComputeFileSize (const fs :: path& pathToCheck)
{
if (fs :: exists(pathToCheck) &&
fs :: is_regular_file(pathToCheck))
{
auto generr=std::error_code{};
auto fsize= fs::file_size(pathToCheck, generr);
if (filesize!= static_cast (-1))
return fsize;
}
return static_cast (-1);
}
By using above-mentioned code, you can easily find the size of a file.
Now let’s see how would you find the last edited time of a file:
auto Entrytime = fs :: last_write_time(entry); time_t cftim = chrono::system_clock::to_time_t(Entrytime); cout<< std::asctime( std::localtime(&cftim));
You see how nice and easy it is.
Note that, most of the methods that work with “path” have two versions mentioned below:
- First that throws: filesystem_error
- And second with error_code, this is system specific
Now I am going to take a bit tricky example. Here, you would see how to traverse the directory tree and display its contents.
Traversing a path
You can traverse a path by using 2 iterators as follows:
- recursive_directory_iterator– it iterates files recursively, but the order of visited files/directories is unspecified. Furthermore, each directory is visited only once.
- directory_iterator
In both above-mentioned iterators, the directories “.” and “..” are skipped.
Consider the following code:
void DisplayDirTree (const fs::path& pathToShow , int lvl)
{
if ( fs::exists(pathToShow) && fs::is_directory (pathToShow))
{
auto leadto = std::string(level * 4, ' ');
for (const auto& entry : fs::directory_iterator(pathToShow))
{
auto fname = entry.path().filename();
if (fs::is_directory (entry.status() ))
{
cout << leadto << "[+] " << fname << "\n";
DisplayDirTree(entry, lvl + 1);
cout<< "\n";
}
else if (fs::is_regular_file(entry.status()))
DisplayFileInfo (entry , leadto , fname);
else
cout<< leadto << " [?]" << fname<< "\n";
}
}
}
In the above-mentioned example, the code does not use a recursive iterator, it does the recursion on its own. Because I wanted to present my files in a managed, tree style order.
You can also start with a root call as follows:
void DisplayDirectoryTree ( const fs::path& pathToShow )
{
DisplayDirectoryTree(pathToShow , 0);
}
Here, the core part is:
for ( auto const & entry : fs::directory_iterator(pathToShow) )
The code will iterate over “entries”, where each entry contains a path object and some additional data that will be used during the iteration.
Well, there is a lot more stuff you can do with the library such as:
- Create, move, copy, files etc.
- Check as well as set file flags
- Work on symbolic links and hard links
- Count disk space usage, stats etc
7. Library changes – Parallel Algorithms
After C++11 and C++14 threading is finally a part of the standard library. As, you can now create “std::thread” and not only depends on a system API or third party libraries. Furthermore, there is also asynchronous processing with futures.
C++14 provides us with a lot of low-level features. But these features are still too tough to use effectively. What our requirement is an abstraction. Ideally, the code must be auto-parallelized/threaded, with some instructions from a programmer.
C++17 takes us a little into this direction as well as allows us to use some more computing power. It has unlocked the auto parallelization/auto vectorization feature for algorithms in SL (Standard Library).
The new feature looks amazingly simple from a user’s perspective. You have a new parameter that you can pass to most of the “std” algorithms. This new parameter is execution policy.
std:: algorithm_name(policy, /* normal arguments… */);
I will get into the detail later, here, let’s just have a general idea that you call an algorithm then you specify how it will be executed. Like it can be parallel, vectorized, or just serial.
Execution policies
The “execution policy” parameter tells the algorithm how it must be executed. You have the following options:
- Parallel Policy: This is a type of execution policy, which is used to disambiguate parallel algorithm overloading as well as indicate that the execution of a parallel algorithm may be parallelized.
Global object: “std::execution::par”
- Sequenced Policy: This is a type of execution policy, which is used to disambiguate parallel algorithm overloading as well as indicate that the execution of a parallel algorithm may be parallelized.
Global object: “std::execution::seq”
- Parallel Unsequenced Policy: This is a type of execution policy, which is used to disambiguate parallel algorithm overloading as well as indicate that the execution of a parallel algorithm may be parallelized or vectorized.
Global object: std::execution::par_unseq
If we have a code like
double mult(double a , double b) {
return a * b;
}
std::transform(
// Left input sequence
a.begin(), a.end(),
b.begin(), // Right input sequence
c.begin(),// Output sequence
mult);
Here, the sequential operations which will be executed using the following instructions:
load a[i] load b[i] mult store into c[i]
With the parallel policy the whole mult() for the “i-th” term will be executed on 1 thread, the operations would not be interleaved. But different i will be on a separate thread.
With “par_unseq mul(“) each operation will be on a separate thread, interleaved. Practically, it can be vectorized as:
load a[i... i+3] load b[i...i+3] mult // 4 elements at once store into c[i...i+3]
In addition, each of the vectorized invocation may happen on a separate thread.
With parallel unsequence, mul() function invocations could be interleaved, so it is not allowed to use vectorized unsafe code: no mutexes or memory allocation.
Moreover, this current approach allows you to offer nonstandard policies. So, library/ compiler vendors may be able to provide their own extensions.
Now let’s have a look, which algorithms has been updated to deal with the new policy parameter.
Algorithm update
Almost all the algorithms from the Standard Library that operates on ranges/containers can handle execution policy parameter.
What we have here?
- all_of, any_of, none_of
- adjacent difference, adjacent find.
- copy
- fill
- find
- count
- equal
- generate
- in place merge, merge
- includes
- inner product
- is heap, is sorted, is partitioned
- lexicographical_compare
- minmax element, min element
- mismatch
- sort copy, partial sort
- move
- n-th elemen
- partition
- replace + variations
- remove + variations
- search
- reverse / rotate
- set difference /symmetric difference / intersection / union
- sort
- swap ranges
- transform
- stable partition
- unique
Consider the following simple example:
std::vector x = genLargeVector(); std::sort(x.begin(), x.end()); // standard seq sort std::sort(std::seq, x.begin(), x.end()); // explicitly seq sort std::sort(std::par, x.begin(), x.end());// permitting parallel execution std::sort(std::par_unseq, x.begin(), x.end()); // permitting vectorization
New algorithms
Some of the existing algorithms was not ready to deal with parallelism, so, some new similar versions are proposed such as:
- for_each_n – it applies a function object to the 1st n-terms of a sequence.
- for_each which is similar to std::for_each with an exception of returning void.
- reduce which is similar to std::accumulate, with an exception of out of order execution.
- inclusive_scan which is similar to std::partial_sum, it includes the i-th input term in i-th sum.
- exclusive_scan which is similar to std::partial_sum, it excludes the i-th input term from i-th sum.
- transform_reduce applies a function and after that reduces out of order
- transform_inclusive_scan applies a function and then calculates inclusive scan
- transform_exclusive_scan applies a function and then calculates exclusive scan
For example, you can use for_each or new for_each_n along with an execution policy, but assuming we do not wish to use the return type of original for_each.
There is another interesting case with “reduce”. This new algo offers a parallel version of accumulate. But it is important to know the difference.
The function of accumulate is to return the sum of all the terms in a range or to return a result of a binary operation, which may be different than just a sum.
std::vector a{11, 21, 31, 41, 51, 61, 71, 81, 91, 111};
int add = std::accumulate(a.begin(), a.end(), /*init*/0);
The algorithm is only sequential. While, a parallel version could try to compute final sum by using a tree approach such as sum sub-ranges, merge the results, then divide and conquer. Such type of method may invoke the binary operation in a nondeterministic order. So, if a binary_op is not commutative or not associative, the behavior is as well non-deterministic.
Like, we will get the same results for reduce and accumulate for a sum of vector of integers. But we may get a little difference in results for a vector of type double or float. The reason is that, the operations of floating are not associative.
8. Library changes – Utils
The most amazing thing regarding C++17 is that it finally combines various patterns and features that were best known but came by various other libraries. Like, for many decades the programmers had been utilizing boost libraries. But now, as I mentioned earlier that many of the boost sub -libraries are merged into standard. This merging process makes transition to the modern C++ language much easier. Now let’s take a quick view of the following features:
- std::variant– as well as the corresponding boost variant
- std::any– it has been adapted from boost any
- std::optional- boosts optional library
- std::search
- std::string_view
Library Fundamentals
Mostly utilities defined now-a-days such as std::optional, std::string_view, std::any, comes from the “Library Fundamentals V1”. Furthermore, it had been in Technical Specs for a short period of time, and then it got merged into standard.
The support is provided by:
- Visual Studio Support
- Libc++ C++1Z Status
- GCC/libstdc++
During the description of the features, I use compiler support. While, for the discussion of library features, I will mention library implementation. And for simplification, I will simply mention the name of compiler such as Clang, GCC, MSVC, because each one has its separate libraries.
Now let’s get to the features:
std::variant
They are the type safe unifications!
The normal “union” allows us to utilize just POD types, which is unsafe. For example, it would not state that which variant is being utilized currently. And by using “std::variant”you can easily access the types that has beens declared.
Consider the following example: std::variant xyz;
According to above-mentioned code, the initialization of xyz is only possible with string, int, or double. A compile-time error will occur, if you try to assign any other type to xyz.
For accessing data, you may use:
- std::getwith type or index of the alternative. If there occur any error, it will throw std::bad_variant_access.
- std::visithas its usage especially for containers along with variants.
- or use std::get_if– as it returns a pointer to element or nullptr.
std::any
It provides a good way to deal with any replace “void*” and “type”.
You are allowed to assign any value to the current any object:
auto x = std::any(11);
x = std::string("You are beautiful :)");
x = 12.0g;
If you wish to read a particular value, then for this purpose you have to achieve a proper cast:
auto x = std::any(11);
std::cout<< std::any_cast(x)<< '\n';
try
{
std::cout<< std::any_cast(x) << '\n';
}
Catch (const std::bad_any_cast& y)
{
std::cout << y.what() << '\n';
}
Note:
- “any”could be empty.
- “any”should not utilize dynamically allocated memory.
std::optional
It is a sophisticated way for returning objects from methods/functions, which are permitted to be empty.
Consider the example below:
std::optional str= GetUserResponse();
if (str)
{
ProcessResponse(*str);
}
else
{
Report("Enter a valid value please");
}
In the above-mentioned code, GetUserResponse return is optional with a likely string inside it. If the user does not input a valid value, str will remain empty. It is more nice as well as expressive rather than using output params, exceptions, nulls, or any other way of handling empty values.
string_view
Move semantics from C++11, has made it much easier to pass strings but still there is a lot of chances to get some temporary copies at the end.
One of the more sophisticated ways to resolve the problem is the use of a string view. Using this view, you will only have a non-owning view of the strings instead of using original string. Mostly it will be a pointer to internal buffer as well as to length. You are allowed to pass this around as well as use most common string methods for manipulation.
The views will work well with string operations such as sub_string. In a usual case, each sub string operation generates the other, minor copy of some part of the string. Using string view, the substr will map an unlike a part of original buffer, without any dynamic allocation or additional memory usage.
One more essential reason for the usage of views is the consistency. what will happen if you use some other implementations for the strings? As, not all developers have the choice to work just with the standard strings. With the help of views, you can only use (or write) cuurrent conversion code, and after that string_view will deal the other strings in the very same way.
Theoretically, string_view is a good and natural alternative for most of const std::string&.
This is essential to note that, string_view is just a non-owning view, so if the real object has been wasted somehow, the view will become useless.
So, if you require a real string, for that there is a separate constructor for std::string, which accepts a string_view. Such as, filesystem library was adapted to deal with string view.
9. Searchers
If you have to search single object in a string, you can simply do that by using find or various other alternatives. The searching patterns (or a sub range) in a string is a bit complicated task.
The simple approach is O(n*m) (here n is the length of whole string, and m is the length of pattern).
But there are some improved alternatives available. Such as, Boyer-Moore string search algorithm with “O(n+m)” complexity.
C++17 has improved “std::search” algorithm in the following ways:
- Execution policy can be used for the execution of the default version of the algo, in a parallel way.
- Now you can offer a Searcher object, which deals with the search.
Moreover, now you are provided with the following 3 searchers:
- boyer_moore_horspool_searcher
- default_searcher
- boyer_moore_searcher
I hope you must have enjoyed as well as learnt a lot from my today’s post. Let me know about your feedback in the comments section below. Good Day
Here’s our top picks of best selling books on C++ 17.




References:

