
This article covers the following topics:
- Errors that a system can recover from, and those that it cannot recover from
- Failing fast and failing loudly
The environment in which your code runs is imperfect: users will provide invalid inputs, external systems will go down, and your code and other code around it will often contain some number of bugs. Given this, errors are inevitable; things can and will go wrong, and as a result you can’t write robust and reliable code without thinking carefully about error cases.
When thinking about errors it’s important to distinguish between errors that a piece of software might want to recover from, and those that there is no sensible way that it could recover from.
This article is taken from the book Good Code, Bad Code by Tom Long. Use the following 35% discount code when ordering this book: nlmycplus21
Recoverability
When thinking about a piece of software, it’s often necessary to think about whether there is a realistic way to recover from a particular error scenario or not. This section will describe what is meant by an error being one that can or cannot be recovered from. It will then go on to explain how this distinction is often context dependent, meaning engineers have to think carefully about how their code might be used when deciding what to do when an error occurs.
Errors that can be recovered from
Many errors are not fatal to a piece of software, and there are sensible ways to handle them gracefully and recover. An obvious example of this is if a user provides an invalid input (such as an incorrect phone number); it would not be a great user experience if, upon entering an invalid phone number, the whole application crashed (potentially losing unsaved work). Instead, it’s better to just provide the user with a nice error message stating that the phone number is invalid, and ask them to enter a correct one.
In addition to things like invalid user inputs, other examples of errors that you likely want a piece of software to recover from are:
- Network errors — if a service that you depend on is unreachable, then it might be best to just wait a few seconds and retry, or else ask the user to check their network connection if your code runs on the user’s device.
- A non-critical task error — for example, if an error occurred in a part of the software that just logs some usage statistics, then it’s probably fine to continue execution.
Generally, most errors caused by something external to a system are things that the system as a whole should probably try to recover from gracefully. This is because they are often things that you should actively expect to happen: external systems and networks go down, files get corrupted, and users (or hackers) will provide invalid inputs.
Note that this is referring to the system as a whole. As we will see in a bit, low-level code is often not well placed to try and recover from errors, and it’s often necessary to signal an error to higher-level code that knows how the error should be handled.
Errors that cannot be recovered from
Sometimes errors occur that there is no sensible way for a system to recover from. Very often these occur due to a programming error where an engineer somewhere has “screwed something up.” Examples of these include the following:
- A resource that should be bundled with the code is missing
- Some code misusing another a piece of code, for example:
- Calling it with an invalid input argument
- Not pre-initializing some state that is required
If there is no conceivable way that an error can be recovered from, then the only sensible thing that a piece of code can do is try to limit the damage and maximize the likelihood that an engineer notices and fixes the problem. Later, we discuss the concepts of failing fast and failing loudly, which are central to this.
Can an error be recovered from?
Most types of error manifest when one piece of code calls another piece of code. Therefore, when dealing with an error scenario, it’s important to think carefully about what other code might be calling your code, and in particular the following:
- Would the caller potentially want to recover from the error?
- If so, how will the caller know that they need to handle the error?
Code is often reused and called from multiple places and if you’re aiming to create clean layers of abstraction, then it’s generally best to make as few assumptions as possible about potential callers of your code. This means that when you’re writing or modifying a function, you are not always in a position to know whether an error state is one that can or should be recovered from.
To demonstrate this consider the following code listing. It contains a function that parses a phone number from a string. If the string is an invalid phone number, then that constitutes an error, but can a piece of code calling this function (and the program as whole) realistically recover from this error or not?
Listing 1 Parsing a phone number
class PhoneNumber {
...
static PhoneNumber parse(String number) {
if (!isValidPhoneNumber(number)) {
... some code to handle the error ... #A
}
...
}
...
}
#A Can the program recover from this or not?
The answer to the question of whether the program can recover from this error or not is that we don’t know unless we know how this function is being used and where it’s being called from.
If the function is being called with a hard-coded value that is not a valid phone number, then it’s a programming error. This is likely not something that the program can recover from. Imagine this is being used in some call-forwarding software for a company that redirects every call to the head office, there is absolutely no way the program can recover from this:
PhoneNumber getHeadOfficeNumber() {
return PhoneNumber.parse(“01234typo56789”);
}
Conversely, if the function is being called with a user-provided value (as in the following snippet) and that input is an invalid phone number, then it is probably something that the program can and should recover from. It would be best to show a nicely formatted error message in the UI informing the user that the phone number is invalid.
PhoneNumber getUserPhoneNumber(UserInput input) {
return PhoneNumber.parse(input.getPhoneNumber());
}
Only the caller of the PhoneNumber.parse() function is in a position to know whether the phone number being invalid is something that the program can recover from or not. In scenarios like this, the author of a function like PhoneNumber.parse() should assume that the phone number being invalid is something that callers may want to recover from.
More generally, if any of the following are true, then an error caused by anything supplied to a function should probably be considered as something that the caller might want to recover from:
- You don’t have exact (and complete) knowledge about everywhere your function might be called from
- There’s even the slimmest chance that your code might be reused in the future
The only real exception to this is where the code’s contract makes it clear that a certain input is invalid and a caller has an easy and obvious way to validate the input before calling the function. An example of this might be an engineer calling a list getter with a negative index (in a language that doesn’t support this); it should be obvious that a negative index would be invalid, and the caller has an easy and obvious way to check this before calling the function if there’s a risk that the index could be negative. For scenarios like this, you can probably safely assume it’s a programming error, and treat it as something that cannot be recovered from. But, it’s still good to appreciate that what might seem obvious to you about how your code should be used might not be obvious to others. If the fact that a certain input is invalid is buried deep in the small print of the coding contract, then other engineers are likely to miss it.
Determining that callers might want to recover from an error is all well and good, but if callers are not even aware that the error can happen, then they’re unlikely to handle it properly. The next section explains this in more detail.
Making callers aware
When some other code calls your code, it will often have no practical way of knowing beforehand that its call will result in an error. For example, what is or isn’t a valid phone number might be quite a complicated thing to determine. “01234typo56789” might be an invalid phone number, but “1-800-I-LOVE-CODE” might be perfectly valid, meaning the rules determining this are clearly somewhat complicated.
In the previous phone number example (repeated in listing 2), the PhoneNumber class provides a layer of abstraction for dealing with the ins-and-outs of phone numbers; callers are shielded from the implementation details, and thus complexity, of the rules that determine what is/isn’t a valid phone number. It would therefore be unreasonable to expect callers to only call PhoneNumber.parse() with valid inputs, because the whole point in the PhoneNumber class is to prevent callers from having to worry about the rules that determine this.
Listing 2 Parsing a phone number
class PhoneNumber { #A
...
static PhoneNumber parse(String number) {
if (!isValidPhoneNumber(number)) {
... some code to handle the error ...
}
...
}
...
}
#A The layer of abstraction for phone numbers
Further to this, because callers to PhoneNumber.parse() are not experts on phone numbers, they might not even realize that the concept of a phone number being invalid exists, or even if they do, they might not expect validation to happen at this point. They might expect it to happen only when the number is dialed, for example.
The author of the PhoneNumber.parse() function should therefore make sure that callers are aware of the possibility that an error might occur. Failure to do this could result in surprises when the error does occur and no-one has written any code to actually handle it. This might lead to user-visible bugs or failures in business-critical logic.
Robustness vs failure
When an error occurs, there is often a choice to be made between:
- Failing, which could entail either making a higher layer of code handle the error or else making the entire program crash
- Trying to deal with the error and carrying on
Carrying on can sometimes make code more robust, but it can also mean that errors go unnoticed and that weird things start happening. This section explains why failure can often be the best option, but how robustness can be built in at appropriate levels in the logic.
Fail fast
Imagine you are in the business of foraging for rare wild truffles and selling them to high-end restaurants. You want to buy a dog that can help you find truffles by sniffing them out. You have two options:
- A dog that is trained to stop and bark as soon as it discovers a truffle. Whenever it does this, you look where its nose is pointing, dig, and hey presto, you’ve found the truffle
- A dog that, after finding a truffle, stays silent, walks for 10 meters or more in random directions, and only then starts barking
Which of these dogs would you choose? Hunting for bugs in code is a bit like hunting for truffles with a dog: at some point the code will bark at you by exhibiting some bad behavior or throwing an error. You’ll know where the code started barking: either where you saw the bad behavior or a line number in a stack trace. But if the barking doesn’t start anywhere near the actual source of the bug, then it’s not very useful.
Failing fast is about ensuring that an error is signaled as near to the real location of a problem as possible. For errors that can be recovered from, this gives the caller the maximum chance of being able to recover gracefully and safely from it; for errors that cannot be recovered from, it gives engineers the maximum chance of being able to quickly identify and fix the problem. In both cases, it also prevents a piece of software from ending up in an unintended and potentially dangerous state.
A common example of this is when a function is called with an invalid argument. Failing fast would mean throwing an error as soon as that function is called with the invalid input, as opposed to carrying on running only to find that the invalid input causes an issue somewhere else in the code some time later.
Figure 1 illustrates what can happen if code doesn’t fail fast: the error may only manifest far away from the actual location of the error, and it can require significant engineering effort to work backwards through the code to find and fix the error.
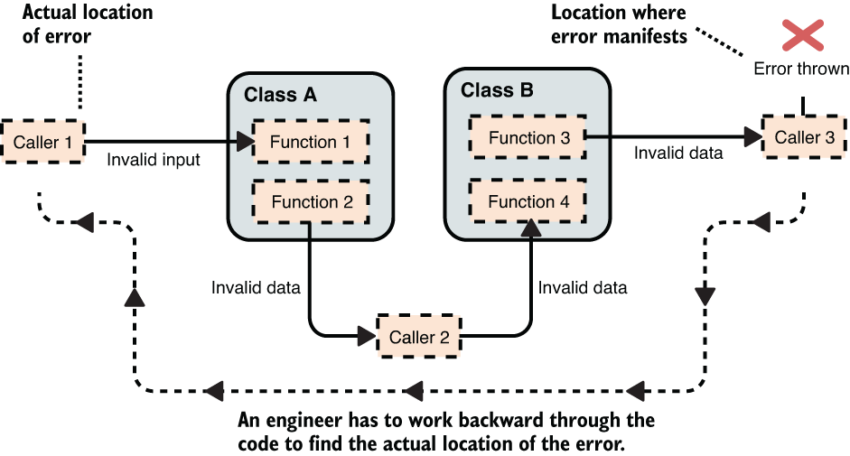
Figure 1 If code doesn’t fail fast when an error occurs, then the error may only manifest much later in some code far away from the actual location of the error. It can require considerable engineering effort to track down and fix the problem.
In contrast, figure 2 shows how failing fast can improve the situation considerably. When failing fast the error will manifest near to its actual location and a stack trace will often provide the exact line number in the code where it can be found.
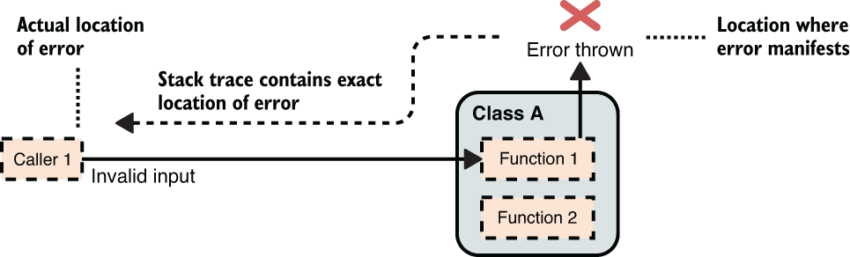
Figure 2 If code fails fast when an error occurs, then the exact location of the error will usually be immediately obvious.
In addition to making things hard to debug, not failing fast can cause code to limp on and potentially cause damage. An example of this might be saving some corrupted data to a database: a bug which may only be noticed several months later, by which time a lot of important data may have been destroyed for good.
As with the dog and the truffle, it’s a lot more useful if code barks as near to the real source of the problem as possible. If the error can’t be recovered from, then it’s also important to make sure that code does indeed bark (and bark loudly) when there’s a bug, as the next section discusses; this is known as failing loudly.
Fail loudly
If an error occurs that the program can’t recover from, then it’s very likely a bug caused by a programming error or some mistake made by an engineer. You obviously don’t want a bug like this in the software and you most likely want to fix it, but you can’t fix it unless you first know about it.
Failing loudly is simply ensuring that errors don’t go unnoticed. The most obvious (and violent) way to do this is to crash the program by throwing an exception (or similar). An alternative is to log an error message, although these can sometimes get ignored depending on how diligent engineers are at checking them and how much other noise there is in the logs. If the code is running on a user’s device, then you might want to send an error message back to the server to log what has happened (as long as you have the user’s permission to do this of course).
If code fails fast and fails loudly, then there is a good chance that a bug will be discovered during development or during testing (before the code is even released). Even if it’s not, then you’ll likely start seeing the error reports quite soon after release and will have the benefit of knowing exactly where the bug occurred in the code from looking at the report.
Scope of recoverability
The scope within which something can or cannot be recovered from, can vary. For example, if you are writing code that runs within a server that handles requests from clients, an individual request may trigger a code path with a bug in it that causes an error. There may be no sensible way to recover within the scope of handling that request, but it may not warrant crashing the whole server. In this scenario, the error cannot be recovered from within the scope of that request, but can be recovered from by the server as a whole. Figure 3 illustrates this.
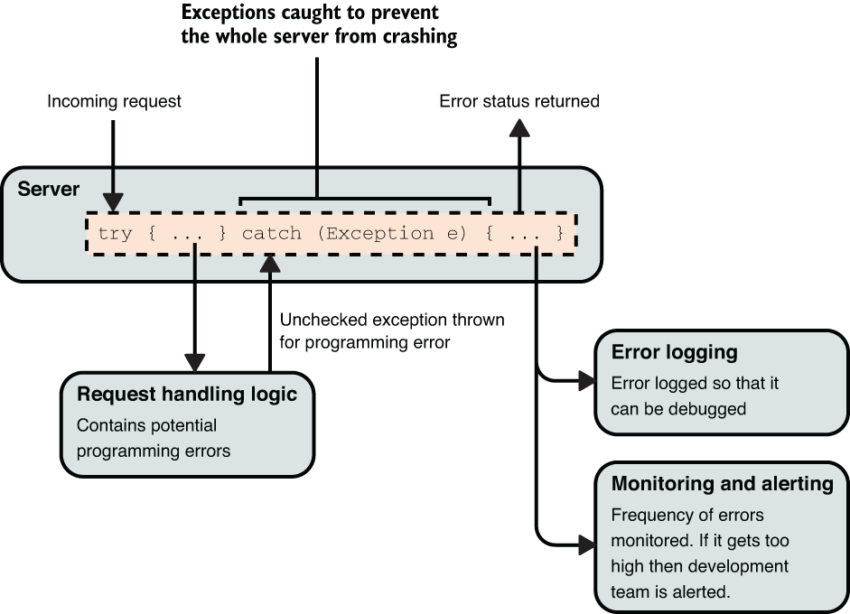
Figure 3 In a server a programming error may occur when processing a single request. Because requests are independent events, it might be best not to crash the whole server when this happens. The error cannot be recovered from within the scope of a single request, but can be recovered from by server as a whole.
| Note | Server frameworks Most server frameworks contain features to allow you to isolate errors for individual requests and map certain types of error to different error responses and handling. It’s therefore unlikely that you’d have to write your own try–catch statement, but something conceptually similar to this will be happening inside the server framework. |
It’s generally good to try and make software robust; crashing a whole server because of one bad request would probably not be a good idea. But it’s also important to make sure that errors don’t go unnoticed, so the code needs to fail loudly. There is often a dichotomy between these two aims. The loudest way to fail is to crash the program, but this obviously makes the software less robust.
The solution to this dichotomy is to ensure that if programming errors are caught, they are logged and monitored in a way that ensures that engineers will notice them. This usually involves logging detailed error information so that an engineer can debug what happened, and ensuring that error rates are monitored and that engineers are alerted if the error rate gets too high.
Don’t hide errors
As you just saw, robustness can be built in by isolating independent or non-critical parts of code to ensure they don’t crash the entire piece of software. This usually needs to be done carefully, sparingly, and in reasonably high-level code. Catching errors from non-independent, critical, or low-level parts of code and then carrying on regardless can often lead to software that doesn’t properly do what it’s meant to. And if errors are not appropriately logged or reported, then problems might go unnoticed by the engineering team.
Sometimes it can seem tempting to just hide an error and pretend it never happened. This can make the code look a lot simpler and avoid a load of clunky error handling, but it’s almost never a good idea. Hiding errors is problematic for both errors that can be recovered from and errors that cannot be recovered from:
- Hiding an error that a caller might want to recover from denies that caller the opportunity to gracefully recover from it. Instead of being able to display a precise and meaningful error message, or fall back to some other behavior, they are instead completely unaware that anything has gone wrong, meaning the software will likely not do what it is meant to.
- Hiding an error that can’t be recovered from likely conceals a programming error. As was established in the earlier subsections about failing fast and failing loudly, these are errors that the development team really need to know about so they can be fixed. Doing this means that the development team may never know about important errors, and the software will contain bugs that may go unnoticed for quite some time.
- In both scenarios, if an error occurs then it generally means that the code is not able to do the thing that a caller was expecting it to do. If the code tries to hide the error, then the caller will assume that every worked fine, when in fact it didn’t. The code will likely limp on but then output incorrect information, corrupt some data, or eventually crash.
The next few subsections cover some of the ways in which code can hide the fact that an error has occurred. Some of these techniques are useful in other scenarios, but when it comes to handling errors, they are all generally a bad idea.
Returning a default value
When an error occurs and a function is unable to return a desired value then it can sometimes seem simpler and easier to just return a default value. The alternative of adding code to do proper error signaling and handling can seem like a lot of effort in comparison. The problem with default values is they hide the fact that an error has occurred, meaning callers of the code will likely carry on as though everything is fine.
Listing 3 contains some code to look up the balance of a customer’s account. If an error occurs while accessing the account store, then the function returns a default value of zero. Returning a default value of zero hides the fact that an error has occurred and makes it indistinguishable from the scenario of the customer genuinely having a balance of zero. If a customer with a credit balance of $10,000 logged in one day to find their balance displayed as zero, they would probably freak out. It would be better to signal the error to the caller so they can just display an error message to the user saying, “Sorry we can’t access this information right now.”
Listing 3 Returning a default value
class AccountManager {
private final AccountStore accountStore;
...
Double getAccountBalanceUsd(Int customerId) {
AccountResult result = accountStore.lookup(customerId);
if (!result.success()) {
return 0.0; #A
}
return result.getAccount().getBalanceUsd();
}
}
#A A default value of zero is returned if an error occurs
There can be scenarios where having default values in code can be useful, but they’re almost never appropriate when it comes to dealing with errors. They break the principles of failing fast and failing loudly, because they cause the system to limp on with incorrect data, and mean that the error will manifest in some weird way later on.
The null-object pattern
A null-object is conceptually similar to a default value, but expands the idea to cover more complicated objects (like classes). A null-object will look like a genuine return value, but all its member functions will either do nothing or return a default value that’s intended to be innocuous.
Examples of the null-object pattern can vary from something as simple as returning an empty list, to something as complicated as implementing a whole class. Here we will just concentrate on the example of an empty list.
The following listing contains a function to look up all the unpaid invoices for a customer. If the query to the InvoiceStore fails, then the function returns an empty list. This could easily lead to bugs in the software. A customer may owe thousands of dollars in unpaid invoices, but if the invoiceStore happens to be down on the day an audit is run, then the error will lead the caller to believe that the customer has no unpaid invoices.
Listing 4 Returning an empty list
class InvoiceManager {
private final InvoiceStore invoiceStore;
...
List<Invoice> getUnpaidInvoices(Int customerId) {
InvoiceResult result = invoiceStore.query(customerId);
if (!result.success()) {
return []; #A
}
return result
.getInvoices()
.filter(invoice -> !invoice.isPaid());
}
}
#A An empty list is returned if an error occurs
The null-object pattern will be covered in detail in chapter 6. As far as design patterns go, it’s a bit of a double-edged sword; there are a few scenarios where it can be quite useful, but as the preceding example shows, when it comes to error handling, it’s often not a good idea to use it.
Doing nothing
If the code in question does something (rather than returning something), then one option is to just not signal that an error has happened. This is generally bad, as callers will assume that the task that the code was meant to perform has been completed. This is very likely to create a mismatch between an engineer’s mental model of what the code does, and what it does in reality. This can cause surprises and create bugs in the software.
Listing 5 contains some code to add an item to a MutableInvoice. If the item being added has a price in a different currency to that of the MutableInvoice, then that is an error and the item will not be added to the invoice. The code does nothing to signal that this error has occurred and that the item has not been added. This is very likely to cause bugs in the software, as anyone calling the addItem() function would expect that the item has been added to the invoice.
Listing 5 Do nothing when an error occurs
class MutableInvoice {
...
void addItem(InvoiceItem item) {
if (item.getPrice().getCurrency() !=
this.getCurrency()) {
return; #A
}
this.items.add(item);
}
...
}
#A If there is a mismatch in currencies the function returns
The previous scenario is an example of just not signaling an error. Another scenario that you may come across is code that actively suppresses an error that another piece of code signals. Listing 6 shows what this might look like. A call to emailService.sendPlainText() can result in an EmailException if an error occurs in sending an email. If this exception occurs then the code suppresses it, and doesn’t signal anything to the caller to indicate that the action failed. This is very likely to cause bugs in the software, as a caller to this function will assume that the email has been sent, when in fact it may not have been.
Listing 6 Suppressing an exception
class InvoiceSender {
private final EmailService emailService;
...
void emailInvoice(String emailAddress, Invoice invoice) {
try {
emailService.sendPlainText(
emailAddress,
InvoiceFormat.plainText(invoice));
} catch (EmailException e) { } #A
}
}
#A The EmailException is caught and then completely ignored
A slight improvement on this would be if an error were logged when the failure happens (listing 7), but this is still almost as bad as the original code in listing 6. It’s a slight improvement because at least an engineer might notice these errors if they looked in the logs. But it’s still hiding the error from the caller, meaning they will assume that the email has been sent, when in fact it has not.
Listing 7 Catching an exception and logging an error
class InvoiceSender {
private final EmailService emailService;
...
void emailInvoice(String emailAddress, Invoice invoice) {
try {
emailService.sendPlainText(
emailAddress,
InvoiceFormat.plainText(invoice));
} catch (EmailException e) {
logger.logError(e); #A
}
}
}
#A The EmailException is logged
| Note | Be careful what you log Another thing that should make you nervous about the code in listing 7 is that the EmailException might contain an email address, which could contain a user’s personal information and be subject to specific data handling policies. Logging that email address to an error log might break those data handling policies. |
As the examples above demonstrate, hiding errors is almost never a good idea. If a company had the code from the previous few listings in their code base, then they’d likely have a lot of unpaid invoices and an unhealthy looking balance sheet. Hiding errors can have real-world (and sometimes severe) consequences. It’s better to signal when an error has occurred, and how to signal errors is covered in detail in the book.
That’s all for this article.
If you want to learn more about this book, you can check it out here.
Use the following 35% discount code when ordering this book: nlmycplus21
